6.7 标志物分析 EMP_marker_analysis
模块EMP_marker_analysis旨在利用机器学习算法寻找多组学数据内的关键特征。需注意,在组学数据分析中,机器学习模型主要有两种用途:第一种是利用机器学习算法筛选具有潜在标志物能力的特征;第二种是基于组学数据构建机器学习预测模型,用于辅助区分不同的组别。由于构建预测模型往往需要多种调参优化,粗暴地使用默认参数常常难以得到理想的结果。因此,模块EMP_marker_analysis的设计目的是帮助用户快速筛选潜在标志物,而非专注于构建和优化预测模型。
6.7.1 基于Boruta算法估计特征的重要性
🏷️示例:
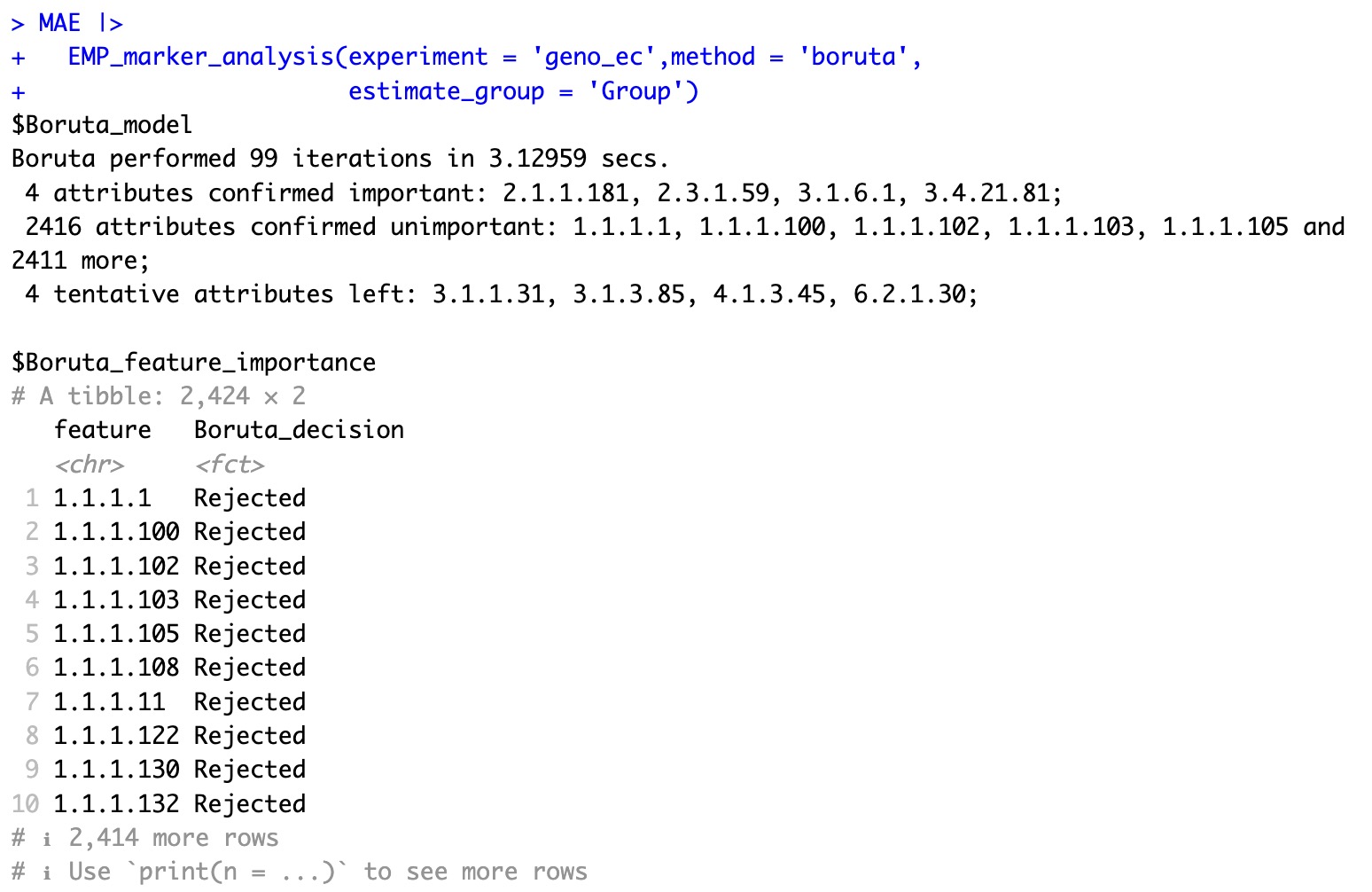
使用Boruta算法可以根据coldata中的分类,快速将数据中的特征分为Confirmed, Tentative和Rejected三类。
MAE |>
EMP_marker_analysis(experiment = 'geno_ec',method = 'boruta',
estimate_group = 'Group')
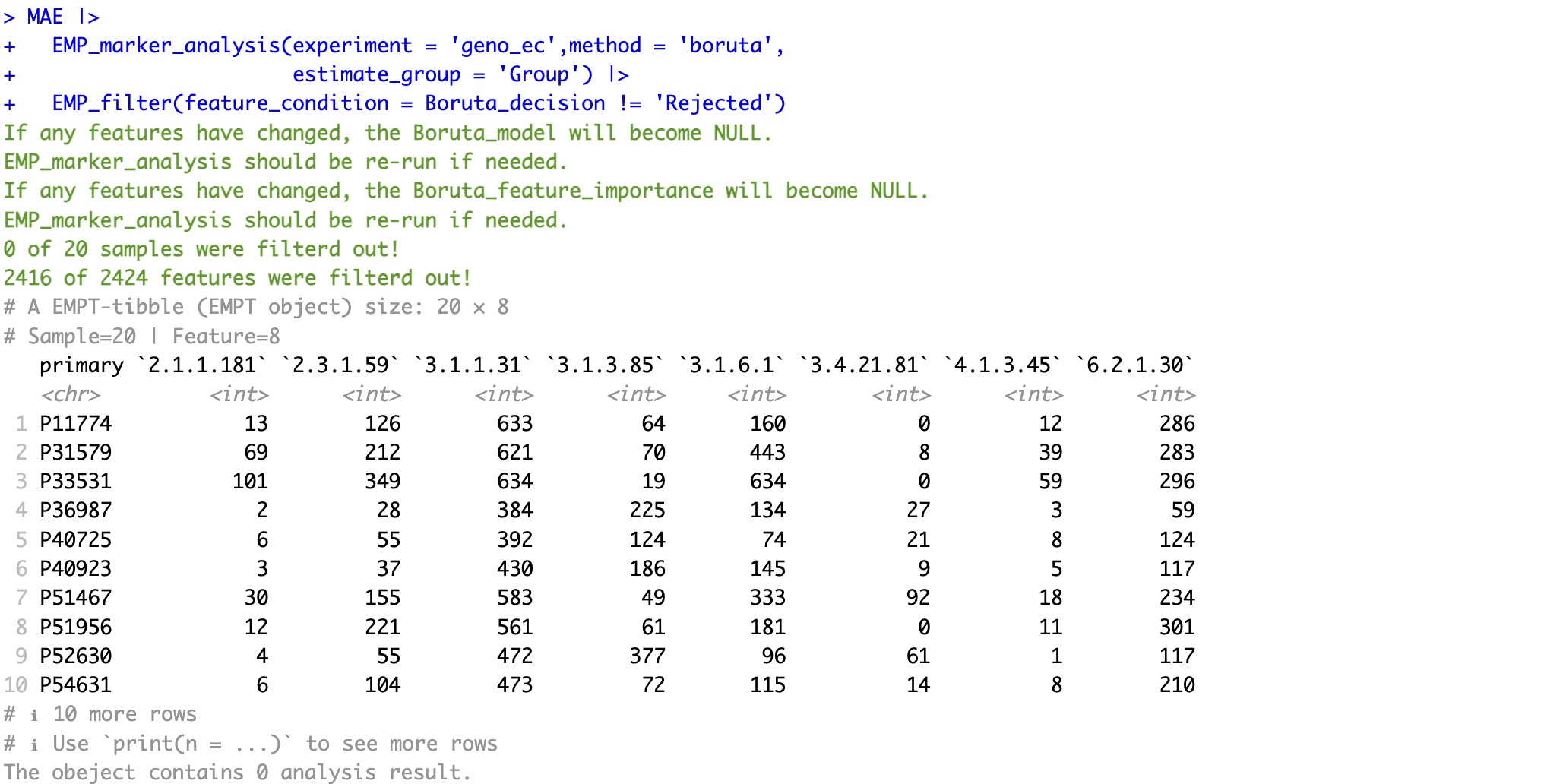
可以使用EMP_filter模块快速筛选所需要的特征,便于其他下游分析。
注意:
EMP_filter适用于所有模型的筛选。
MAE |>
EMP_marker_analysis(experiment = 'geno_ec',method = 'boruta',
estimate_group = 'Group') |>
EMP_filter(feature_condition = Boruta_decision != 'Rejected')
6.7.2 基于randomforest算法估计特征的重要性
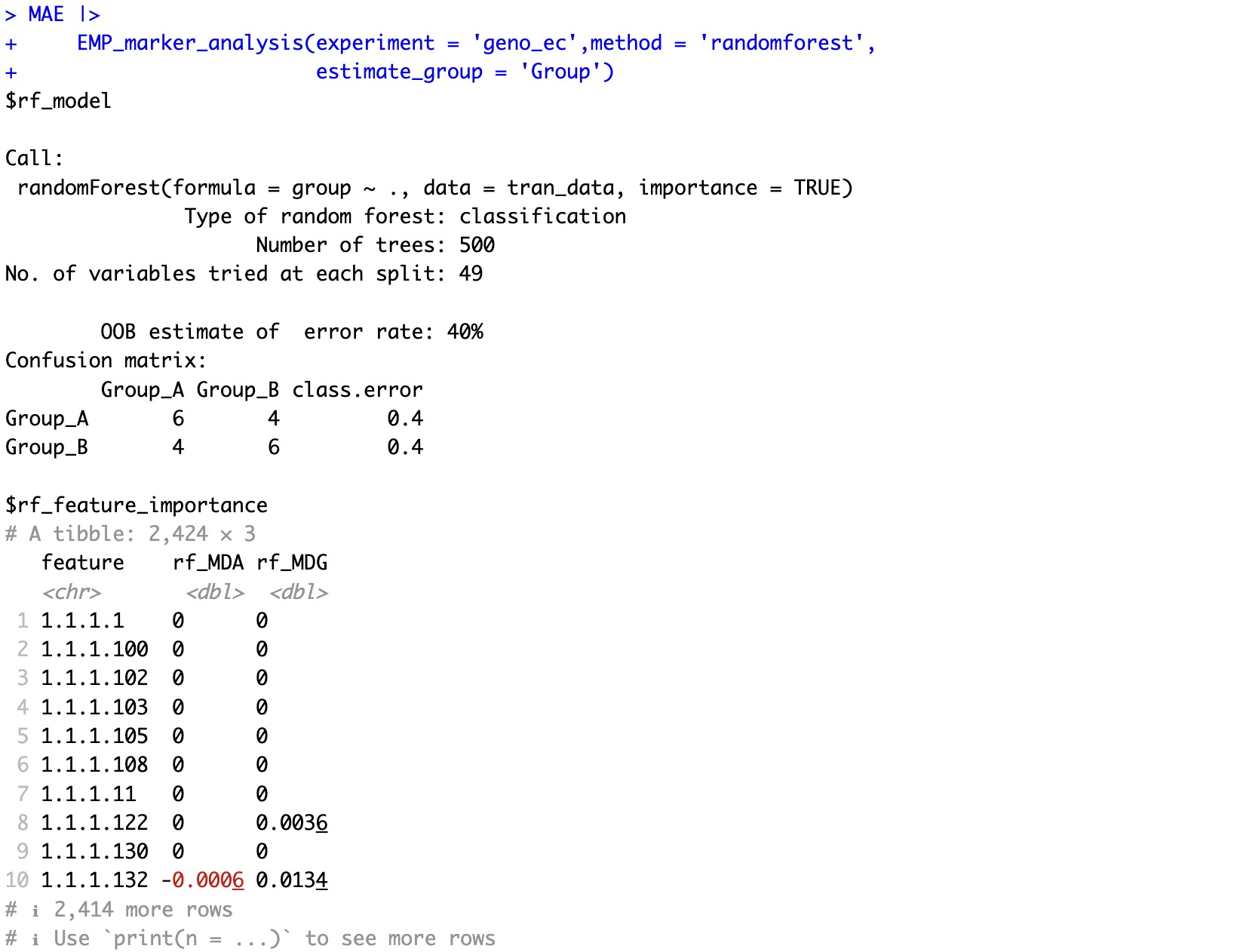
🏷️示例1:基于随机森林分类进行特征的重要性评估。
MAE |>
EMP_marker_analysis(experiment = 'geno_ec',method = 'randomforest',
estimate_group = 'Group')
🏷️示例2:基于随机森林回归进行特征的重要性评估。
MAE |>
EMP_marker_analysis(experiment = 'geno_ec',method = 'randomforest',
estimate_group = 'BMI')

6.7.3 基于xgboost算法估计特征的重要性
注意:
①使用xgboost算法时,需要通过参数
②进行分类模型时,必须指定参数
③进行回归模型时,必须指定参数
④参数
①使用xgboost算法时,需要通过参数
objective指定模型。当参数estimate_group的指定值为二分类变量时,需指定参数objective = 'binary:logistic';当参数estimate_group的指定值为多分类变量时,需指定参数objective = multi:softmax;参数estimate_group的指定值为连续型变量时,需指定参数objective = 'reg:squarederror'。更多详情请参考xgboost包。②进行分类模型时,必须指定参数
xgboost_run='classify'。③进行回归模型时,必须指定参数
xgboost_run='regression'。④参数
xgboost_run指定错误将会导致计算结果错误。
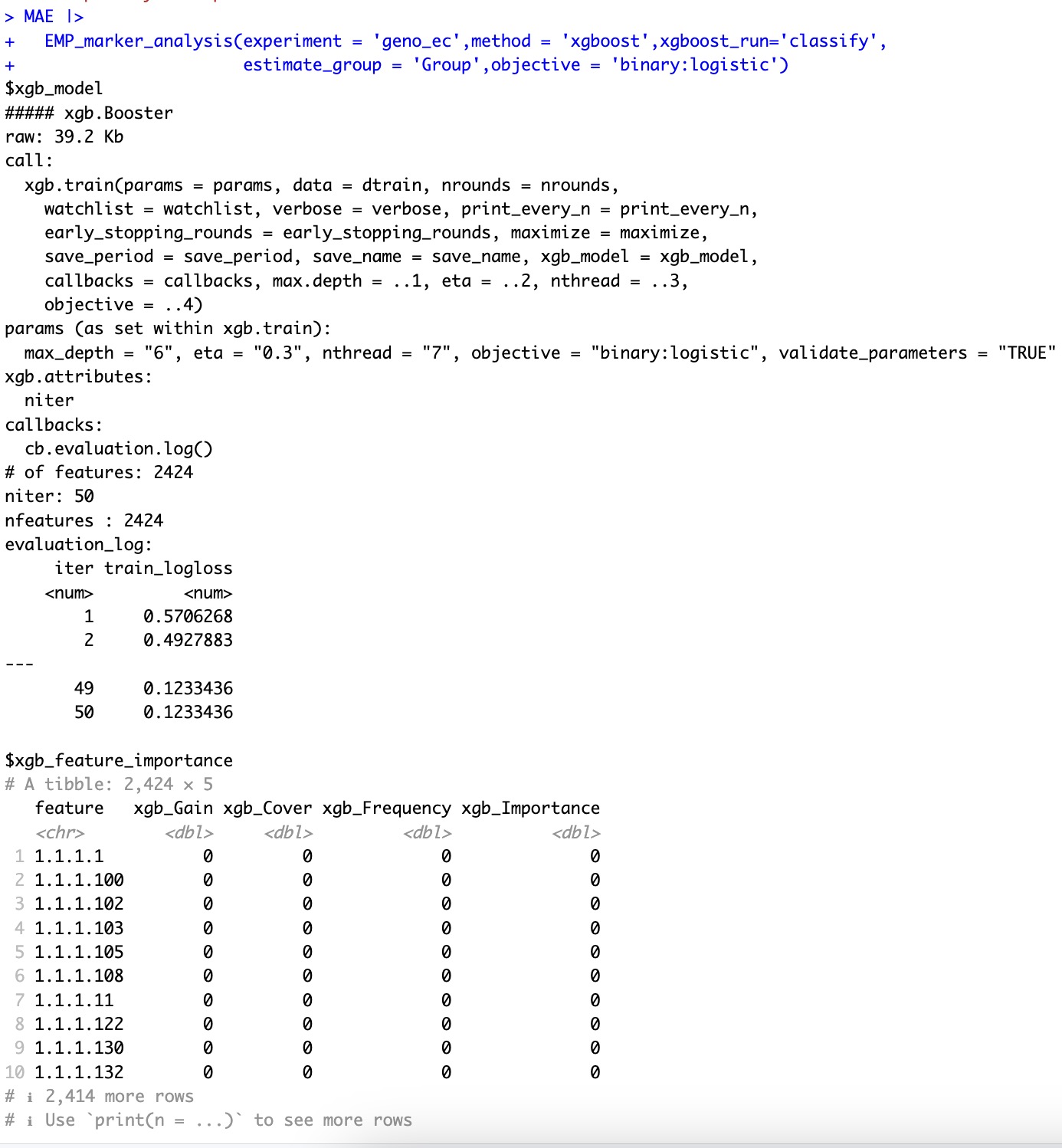
🏷️示例1:基于xgboost分类算法进行特征重要性评估。
MAE |>
EMP_marker_analysis(experiment = 'geno_ec',method = 'xgboost',xgboost_run='classify',
estimate_group = 'Group',objective = 'binary:logistic')
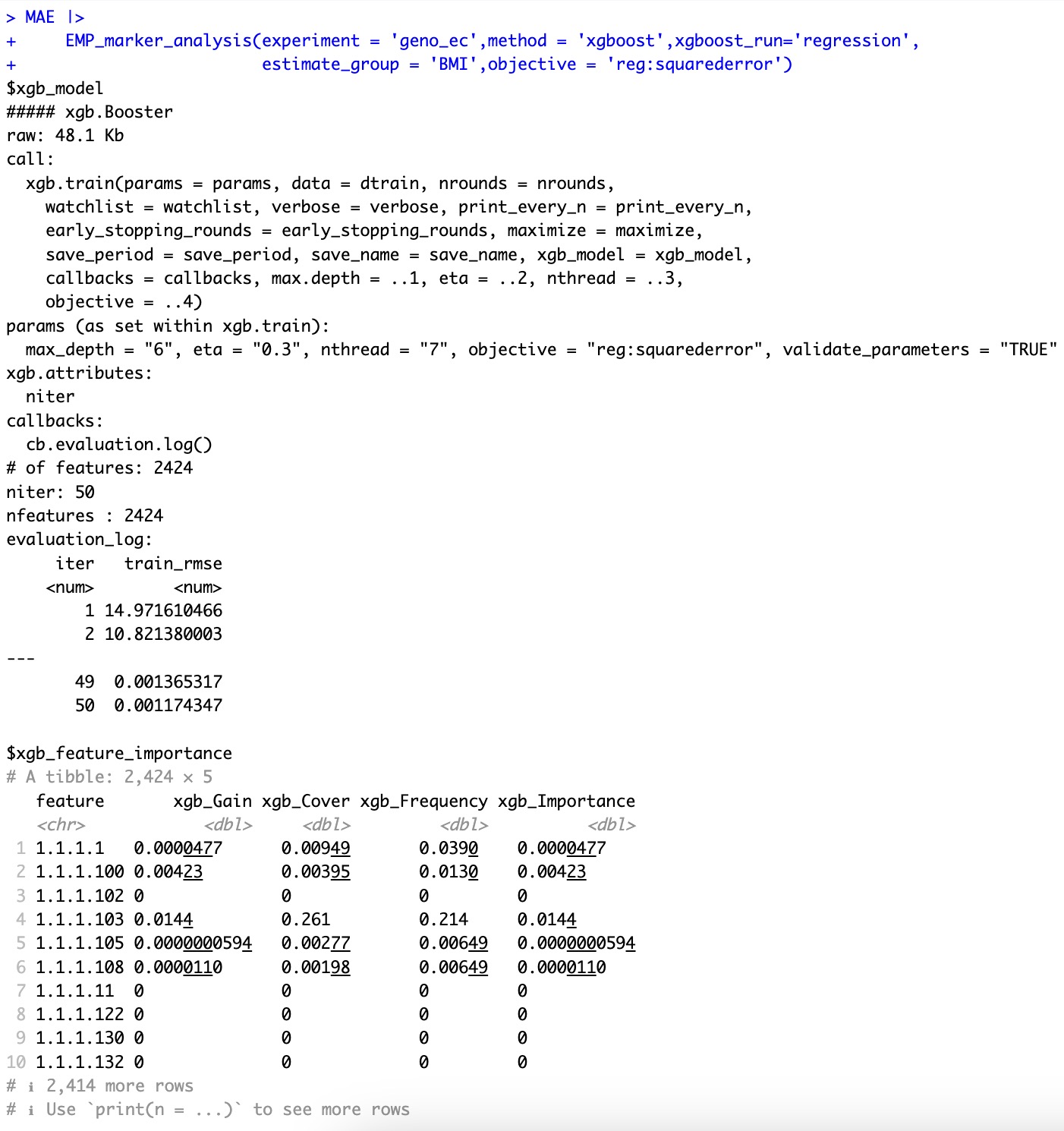
🏷️示例2:基于xgboost回归算法进行特征的重要性评估。
MAE |>
EMP_marker_analysis(experiment = 'geno_ec',method = 'xgboost',xgboost_run='regression',
estimate_group = 'BMI',objective = 'reg:squarederror')
6.7.4 基于Lasso算法估计特征的重要性
🏷️示例:
MAE |>
EMP_marker_analysis(experiment = 'geno_ec',method = 'lasso',
estimate_group = 'BMI')
